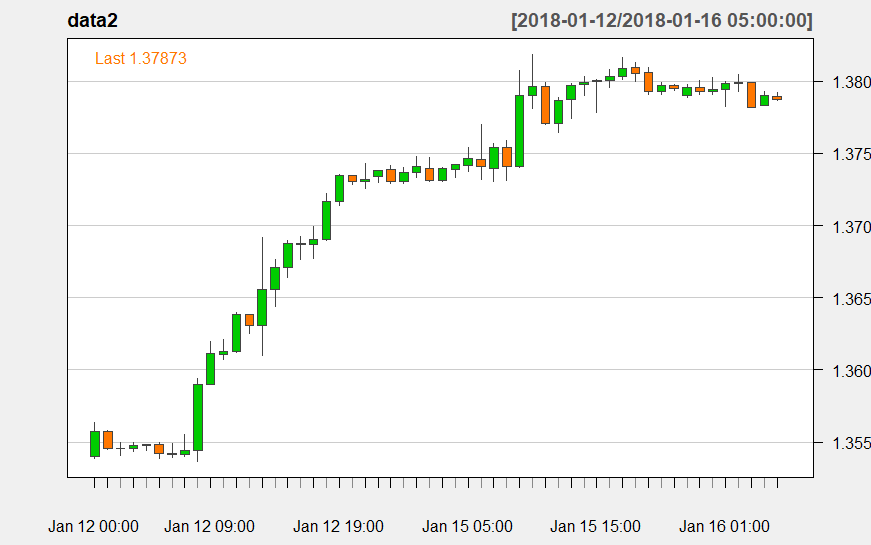
When designing algorithmic trading systems, knowing the direction of the market can help a lot in improving the accuracy of the signals. In this post I will try to develop an algorithmic trading system that attempts to predict the market direction using candlestick patterns and machine learning. Candlestick patterns get widely used by professional traders when making buy/sell decisions. I personally use candlestick patterns a lot in opening and closing trades. I use high and low of the previous candlestick pattern to place the stop loss. But there are problems. Candlestick patterns are vague and imprecise most of the time. You cannot use them alone. You need to use other indicators alongwith candlestick patterns to improve the accuracy of your buy/sell decisions. It take experiences to correctly interpret these patterns and just like other patterns there is a chance of failure that we have a false pattern. How can we develop an algorithm that can use these candlestick patterns in predicting the market? Did you read a previous post on how to develop Algorithmic Trading Strategies using R? In this post, I try to go into great detail and explore how we can use machine learning on candlestick patterns and what level of accuracy can we achieve in our trading signals. In this post we first fuzzify candlestick patterns and then use machine learning as well as deep learning to forecasting future price action. Below is the candlestick chart of GBPUSD on 1 hour timeframe. Did you notice the candlestick patterns on the left of the chart are predicting price rise?
When we deal with financial data, we are in essence dealing with a time series. Read the post on how to predict financial time series using GARCH model.Most of the time we are only dealing with the closing price at the end of some interval like 30 minute, 60 minute, 240 minute, daily or weekly. Most of the literature on time series analysis just uses the closing price for each interval to develop a model which is then used to make the predictions in the future. But we all know in between each interval we have the high price as well as the close price which contains a lot of information that we ignore when we only deal with the closing price. If you have been trading for a while and know how to read candlestick charts, you know that a candlestick body and the upper shadow and the lower shadow have information that we can use in predicting price in near future. This is the important question how to incorporate that information in our forecasting algorithm. This is precisely what we will do now. Below you can see a bullish as well as a bearish candle. In the figure below, you can see the real body, upper shadow and the lower shadow for both a bearish and a bullish candle.
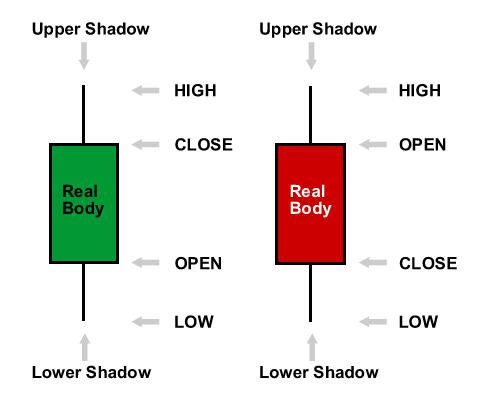
In the above figure you can see both a bullish and bearish candle. You can see the upper shadow, the lower shadow and the candle body. Read the post on the only candlestick pattern you will ever need to making winning trades. We will be using Fuzzy Logic in modeling these candlestick patterns. Fuzzy Logic is not known to many traders. In the recent years, fuzzy logic has become very popular and a lot of research papers have been written showing how fuzzy logic can be applied to many practical areas. Unlike classical logic where everything is either TRUE or FALSE, in fuzzy logic we have shades of grey in between. I explain fuzzy logic more below. First we need to read the data and then define the variables body, upper shadow and the lower shadow. As I said, we will be using R. R is a powerful language that can help you a lot in building powerful algorithmic trading systems. Below I have provided the code that builds a forecasting model based on the candlestick pattern body and the upper shadow and the lower shadow.
#Fuzzy Candlestick Pattern Forecasting Algorithm
# Import the csv file
data1 <- read.csv("D:/Shared/MarketData/GBPUSD60.csv",
header=FALSE)
colnames(data1) <- c("Date", "Time", "Open", "High",
"Low", "Close", "Volume")
library(quantmod)
library(caret)
data2 <- as.xts(data1[,-(1:2)],
as.POSIXct(paste(data1[,1],data1[,2]),
format='%Y.%m.%d %H:%M'))
N <- 600
data2 <- data2[(nrow(data2)-N):(nrow(data2)-1), ]
data2 <- data2[, -5]
#plot the candle chart
#candleChart(data2,theme='white', type='candles',
# subset='last 100 days')
#find the max of open and close
data2$maxOC <- ifelse((data2$Open-data2$Close)>0,
data2$Open, data2$Close)
#fine the min of the open and close
data2$minOC <- ifelse((data2$Open-data2$Close)>0,
data2$Close, data2$Open)
#calculate the previous trend
data2$Trend <- 10000*diff(data2$Close, lag=24)
Imax1 <- max(data2$Trend, na.rm = TRUE)
Imin1 <- min(data2$Trend, na.rm = TRUE)
Imax1
Imin1
ceiling(Imax1)
floor(Imin1)
#calculate the color of the candle
data2$Color <- 10000*(data2$Open - data2$Close)
#calculate the upper shadow, lower shadow and the body
data2$Lupper <-ifelse((data2$Open-data2$Close)>0,
10000*(data2$High-data2$Open),
10000*(data2$High-data2$Close))
data2$Llower <- ifelse((data2$Open-data2$Close)>0,
10000*(data2$Close-data2$Low),
10000*(data2$Open-data2$Low))
data2$Lbody <- ifelse((data2$Open-data2$Close)>0,
10000*(data2$Open-data2$Close),
10000*(data2$Close-data2$Open))
#calculate the daily variation
#calculate the daily variation
data2$Pips <- 10000*diff(data2$Close, lag=24)
data2$Pips <- lag(data2$Pips, k=-24)
#View(data2)
In the above model, first we calculate the trend which is just the cumulative return of the past 24 candles. We will be developing a model for predicting the price after 24 hours. Since we are using 1 hour candles, 24 hours means we will predict price after 24 hours. If the price prediction is up, our indicator will give a buy alert and if the price prediction after 24 hours is negative, our indicator will give a sell signal. We can easily use this model for lower timeframes like 30 minute, 60 minute and 240 minutes as well as higher timeframe like the weekly. So don’t worry about the timeframe for now. Focus on the model. We will be able to use it on any timeframe. After calculating the trend, I have calculated the candle body which I have given the name Lbody and the candle upper shadow which I call the Lupper and the lower shadow which I call Llower. Did you read the post on 8 machine learning algorithms that can help you in building powerful algorithmic trading strategies?
Candle body is just the difference of the open and close price without the sign meaning if the candle is bullish we calculate candle body by subtracting open from close. In case the candle is bearish than we subtract close from open. We take care of the bullish and bearish candle by using the variable Color which is the difference of open with close so it has a sign. Upper shadow is also without sign. If the candle is bullish we subtract close from high and if the candle is bearish we subtract open from high. Below I have calculated the median of the candle body, upper shadow and the lower shadow.
#calculate the universe of discourse #max(Imax1, Imin1) #UoD <- seq(floor(Imin1), ceiling(Imax1), length.out=8) #define the body length a1 <- median(data2$Lbody) #a1 <- mean(data2$Lbody) a1 #define the candle upper shadow length a2 <- median(data2$Lupper) #a2 <- mean(data2$Lupper) a2 #define the candle lower shadow length a3 <- median(data2$Llower) #a3 <- mean(data2$Llower) a3
In the above code, I have calculated the mean as well the median of the candle body, candle upper shadow as well as candle lower shadow. When we do data analysis, it is always a good idea to look at the summary statistics of each variable that we want to use as a feature in our model. I have used GBPUSD daily data. If you check the above code, I have used 600 daily candles in the input dataframe. Below is the summary statistics for the previous trend.
summary(data2$Trend) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's -125.60 -22.75 10.95 15.60 47.52 210.10 24
Above is the summary statistics for Previous Trend. You can see the minimum is -125 pips and the maximum is 210 pips. Do you remember 1192 pips down movement in one day? If you check this downward movement took place on 2016-06-24 just when the Brexit vote results got announced. It was a close call. When Brexit vote result got announced, GBPUSD fell down like a stone. Now in old days, statisticians would call it an outlier that would skew the results. So they would take it out of the data. So you should keep this in mind these black swan events when market can move a lot like 1192 pips in just 24 days. In our data the minimum price movement is 125 pips and the maximum price movement is 210 pips. Extreme values are important in data analysis. Don’t be afraid of them. Below is the summary for Pips!
> summary(data2$Pips) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's -125.60 -22.75 10.95 15.60 47.52 210.10 24
Above is the summary statistics for Pips.We will not be directly using this Pips variable that we have calculated. We will use a categorical variable with two values: BUY and SELL. When we have a positive Pips value we will classify it as BUY and when we have a negative Pips value we will classify it as SELL. Read this post on an AI Forex System. Below is the summary statistics for candle body, candle upper shadow and the candle lower shadow! It is always a good idea to become familiar with data before you start developing a algorithmic trading model.
> summary(data3$Body1) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 0.000 1.100 2.800 3.995 5.600 35.800 1 > summary(data3$UpperShadow1) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.000 1.100 2.700 4.247 5.400 123.500 > summary(data3$LowerShadow1) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.000 2.100 4.900 7.222 9.725 54.800
Above you can see, the median candle body is 2.8 pips while the mean candle body is 4 pips. Minimum candle body is zero pips and the maximum candle body is 35 pips. In the same manner, the median candle upper shadow is 2.7 pips while the mean candle upper shadow is 4.2 pips while the median candle lower shadow is 4.9 pips while the mean candle lower shadow is 7.22 pips. In the candle body summary statistics you can again see the Another extreme event that you should remember is GBPUSD Flash Crash. You can check this the GBPUSD Flash Crash took place on 2016-10-07. Looking at the summary statistics makes you aware of the data. By looking at the above summary statistics for the Previous Trend, Pips, Candle Body, Candle Upper Shadow and the Candle Lower Shadow, we know it better now. Read this post on how to use support vector machines in predicting stock returns. Candlestick patterns are universal. You can use this algorithmic trading strategy on stocks, commodities, currencies and cryptocurrencies. Yes, cryptocurrencies too! Below I have done more data wrangling to process the data into shape that we will use in building a fuzzify model.
data2 <- cbind(data2,data2,data2, data2, data2, data2)
#View(data2)
data2$Open.1 <- lag(data2$Open.1)
data2$High.1 <- lag(data2$High.1)
data2$Low.1 <- lag(data2$Low.1)
data2$Close.1 <- lag(data2$Close.1)
data2$Open.2 <- lag(data2$Open.1)
data2$High.2 <- lag(data2$High.1)
data2$Low.2 <- lag(data2$Low.1)
data2$Close.2 <- lag(data2$Close.1)
data2$Open.3 <- lag(data2$Open.2)
data2$High.3 <- lag(data2$High.2)
data2$Low.3 <- lag(data2$Low.2)
data2$Close.3 <- lag(data2$Close.2)
data2$Open.4 <- lag(data2$Open.3)
data2$High.4 <- lag(data2$High.3)
data2$Low.4 <- lag(data2$Low.3)
data2$Close.4 <- lag(data2$Close.3)
data2$Open.5 <- lag(data2$Open.4)
data2$High.5 <- lag(data2$High.4)
data2$Low.5 <- lag(data2$Low.4)
data2$Close.5 <- lag(data2$Close.4)
data2$Lupper.1 <- lag(data2$Lupper.1)
data2$Llower.1 <- lag(data2$Llower.1)
data2$Lbody.1 <- lag(data2$Lbody.1)
data2$Lupper.2 <- lag(data2$Lupper.1)
data2$Llower.2 <- lag(data2$Llower.1)
data2$Lbody.2 <- lag(data2$Lbody.1)
data2$Lupper.3 <- lag(data2$Lupper.2)
data2$Llower.3 <- lag(data2$Llower.2)
data2$Lbody.3 <- lag(data2$Lbody.2)
data2$Lupper.4 <- lag(data2$Lupper.3)
data2$Llower.4 <- lag(data2$Llower.3)
data2$Lbody.4 <- lag(data2$Lbody.3)
data2$Lupper.5 <- lag(data2$Lupper.4)
data2$Llower.5 <- lag(data2$Llower.4)
data2$Lbody.5 <- lag(data2$Lbody.4)
data2$maxOC.1 <- lag(data2$maxOC.1)
data2$minOC.1 <- lag(data2$minOC.1)
data2$maxOC.2 <- lag(data2$maxOC.1)
data2$minOC.2 <- lag(data2$minOC.1)
data2$maxOC.3 <- lag(data2$maxOC.2)
data2$minOC.3 <- lag(data2$minOC.2)
data2$maxOC.4 <- lag(data2$maxOC.3)
data2$minOC.4 <- lag(data2$minOC.3)
data2$maxOC.5 <- lag(data2$maxOC.4)
data2$minOC.5 <- lag(data2$minOC.4)
data2$Color.1 <- lag(data2$Color.1)
data2$Color.2 <- lag(data2$Color.1)
data2$Color.3 <- lag(data2$Color.2)
data2$Color.4 <- lag(data2$Color.3)
data2$Color.5 <- lag(data2$Color.4)
#View(data2)
data2 <- data2[ ,c(-19, -24, -31,-36,-43,-48,-55,-60,-67,-72)]
data2 <- data2[, c(7, 1,2,3,4,5,6,8,9,10,11,13,14,15,16,
17,18,19,20,21,22,23,24,25,26,27,28,29,
30,31,32,33,34,35,36,37,38,39,40,41,
42,43,44,45,46,47,48,49,50,51,52,53,
54,55,56,57,58,59,60,61,62,12)]
#View(data2)
data3 <- data2
data3 <- data3[, c(-6,-7,-16,-17,-26,-27,-36,-37,-46,-47,
-56,-57)]
data3 <- data3[, -(42:49)]
data3 <- data3[, c(-3,-4,-11,-12,-19,-20, -27,-28,-35,-36)]
colnames(data3) <- c("PreviousTrend", "OpenStyle1",
"CloseStyle1", "Color1",
"Body1", "UpperShadow1",
"LowerShadow1", "OpenStyle2",
"CloseStyle2",
"Color2", "Body2", "UpperShadow2",
"LowerShadow2",
"OpenStyle3",
"CloseStyle3", "Color3",
"Body3", "UpperShadow3",
"LowerShadow3",
"OpenStyle4",
"CloseStyle4", "Color4",
"Body4", "UpperShadow4",
"LowerShadow4",
"OpenStyle5",
"CloseStyle5", "Color5",
"Body5", "UpperShadow5",
"LowerShadow5",
"Variation")
data3 <- data3[, c(-1,-32)]
data3 <- as.data.frame(data3)
Above code is just data wrangling and data pre-processing before we build our fuzzy candlestick pattern model. We will be using the previous trend as well as the past 3 candles as input to predict the output that I have called the variation.
How To Fuzzify The Candlestick Patterns?
I have developed a course on how to use fuzzy logic in trading. if you are interested, you can take a look at my course R Fuzzy Logic for Traders. In the course I explain how to fuzzify data using different membership functions. We will fuzzify the input data. If you don’t know anything about fuzzy logic, let you can take a look at my course R Fuzzy Logic for Traders. In each candlestick there are three variables, the body the upper shadow and the lower shadow. Do you remember the Doji candle? Doji has a very small candle body. When the open and close is almost the same we have a Doji candle. Doji can give you strong clues about trend continuation and trend reversal. In the figure below you can see the fuzzy membership functions for candle body, upper shadow and the lower shadow. We will be using the median candle body, upper shadow and lower shadow.
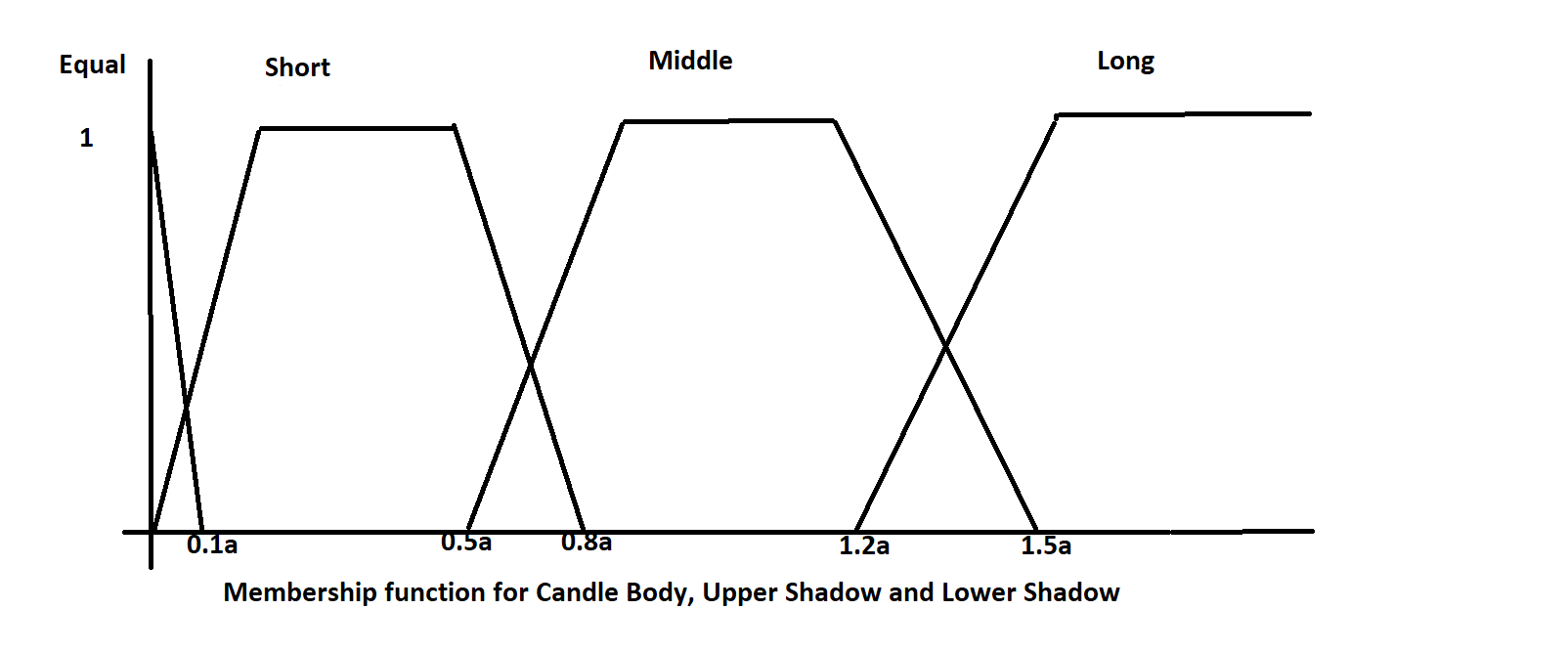
Above is the plot of the fuzzy membership functions for the candle body, upper shadow and the lower shadow. All have four linguistic values Equal, Short, Middle and Long. As said above I have used median of the candle body as well as the upper shadow and the lower shadow instead of the mean. Median is not affected by outliers while mean gets affected by outliers. You can use mean, it wont make much difference. Everything is relative when we use candlestick patterns. We have used a window of 600 one hour candles to calculate the median. In the same manner each candle position relative to the previous candle is important. We model that using Open Style and Close Style variables. Below is the chart of Open Style and Close Style variables.
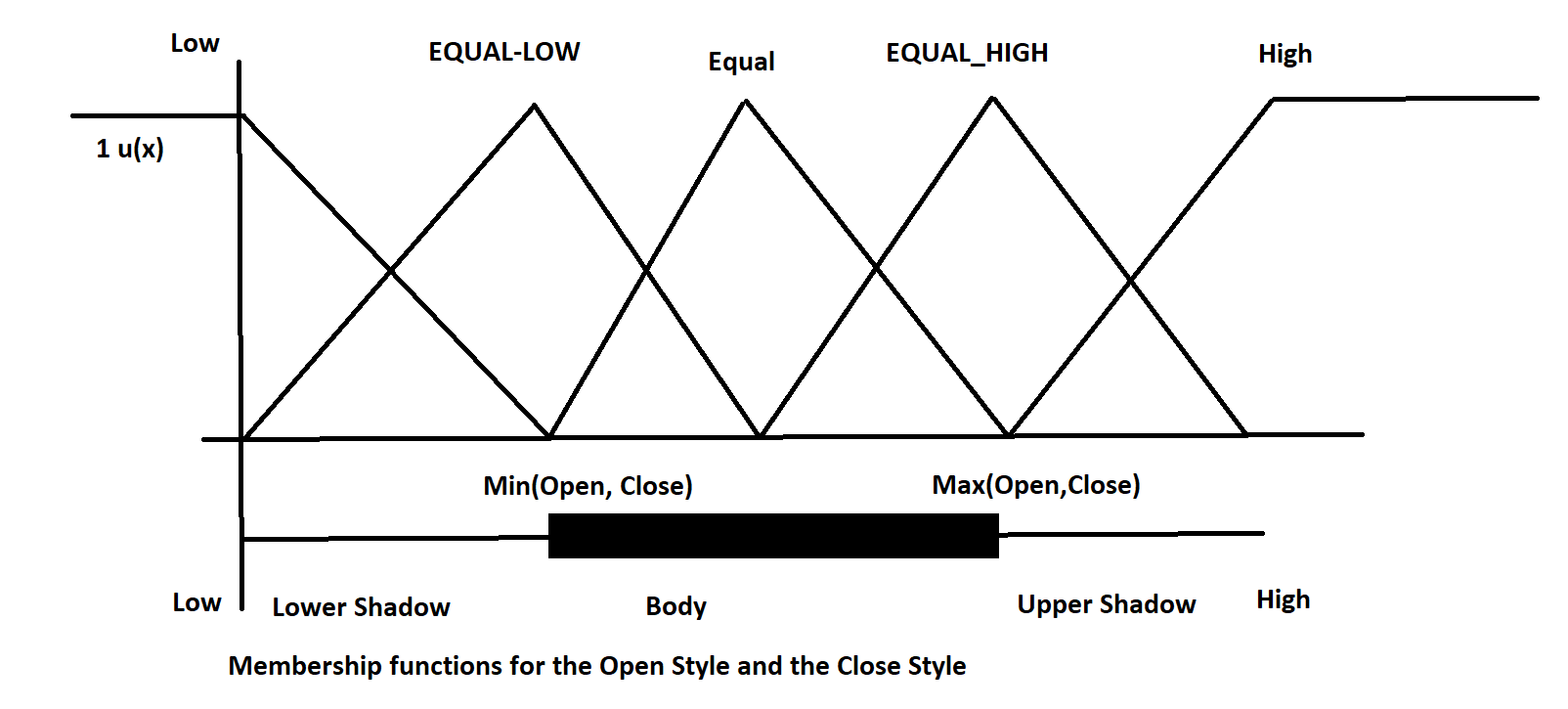
Above is the fuzzy membership function for the Open Style and the Close Style. Open Style has five linguistic variables: OPEN_LOW, OPEN_EQUAL_LOW, OPEN_EQUAL, OPEN_EQUAL_HIGH and OPEN_HIGH. In the same manner, Close Style has five linguistic variables: CLOSE_LOW, CLOSE_EQUAL_LOW, CLOSE_EQUAL, CLOSE_EQUAL_HIGH and CLOSE_HIGH.
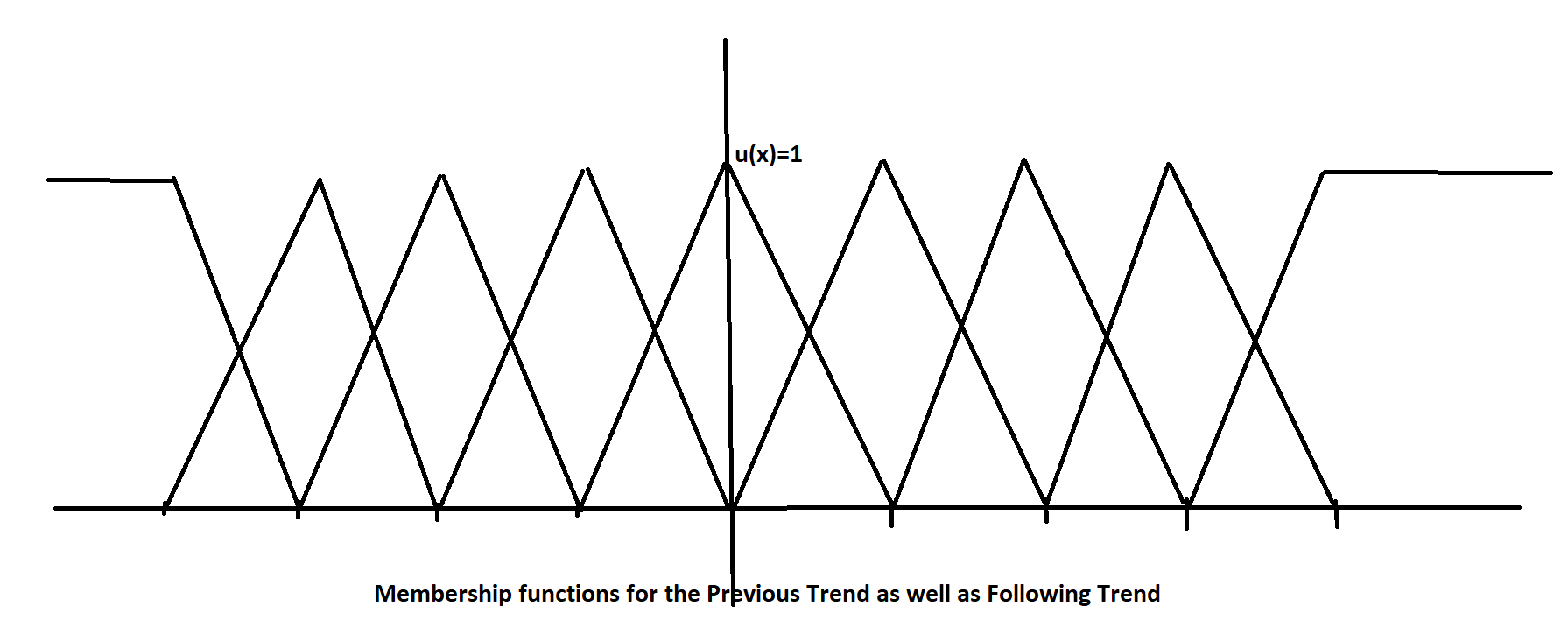
Above is the fuzzy membership function for the Trend. In this model, we will not be using the Trend variable. But in the above figure you can see how you can fuzzify the Trend variable. Left is the minimum trend value and the right is the maximum trend value. I have used FRBS R package. This is a powerful fuzzy relation based system package that you can use to develop your algorithmic trading strategies. The important thing is the build the fuzzfier that fuzzifies the input data.
#demo(WM.GasFur)
#demo(FRBS.Mamdani.Manual)
#demo(FRBS.TSK.Manual)
#demo(FRBS.Manual)
## Define number of linguistic terms of input variables.
## PreviousTrend has 6 linguistic terms
##CandleBody has got 4 linguistic terms
##CandleUpperShadow has got 4 linguistic terms
## CandleLowerShadow has got 4 linguistic terms
##OpenStyle has got 5 linguistic terms
##CloseStyle has got 5 linguistic terms
##FollowingTrend hast got 8 linguistic terms
## Define number of linguistic terms of input variables.
num.fvalinput <- matrix(c(3, 4, 4,4,5,5,#Candle 1
3, 4,4,4,5,5, #Candle 2
3, 4, 4,4,5,5, #Candle 3
3, 4, 4,4,5,5, #Candle 4
3, 4, 4,4,5,5), nrow=1) #Candle 5
## Give the names of the linguistic terms of each input variables.
PreviousTrend <- c("EXTREME_BEARISH", "STRONG_BEARISH",
"NORMAL_BEARISH", "WEAK_BEARISH",
"RANGING", "WEAK_BULLISH","NORMAL_BULLISH",
"STRONG_BULLISH", "EXTREME_BULLISH")
Color1 <-c("CROSS","BULLISH","BEARISH")
Body1 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
UpperShadow1 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
LowerShadow1 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
OpenStyle1 <- c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
CloseStyle1 <- c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
Color2 <-c("CROSS","BULLISH","BEARISH")
Body2 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
UpperShadow2 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
LowerShadow2 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
OpenStyle2 <- c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL", "OPEN_EQUAL_HIGH",
"OPEN_HIGH")
CloseStyle2 <- c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
Color3 <-c("CROSS","BULLISH","BEARISH")
Body3 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
UpperShadow3 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
LowerShadow3 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
OpenStyle3 <- c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
CloseStyle3 <- c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
Color4 <-c("CROSS","BULLISH","BEARISH")
Body4 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
UpperShadow4 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
LowerShadow4 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
OpenStyle4 <- c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
CloseStyle4 <- c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
Color5 <-c("CROSS","BULLISH","BEARISH")
Body5 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
UpperShadow5 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
LowerShadow5 <- c("EQUAL", "SHORT", "MIDDLE", "LONG")
OpenStyle5 <- c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
CloseStyle5 <- c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
Variation <- c("EXTREME_BEARISH", "STRONG_BEARISH",
"NORMAL_BEARISH", "WEAK_BEARISH",
"RANGING", "WEAK_BULLISH","NORMAL_BULLISH",
"STRONG_BULLISH", "EXTREME_BULLISH")
names.varinput <- c(PreviousTrend, OpenStyle1,
CloseStyle1, Color1,
Body1, UpperShadow1,
LowerShadow1, OpenStyle2, CloseStyle2,
Color2, Body2, UpperShadow2, LowerShadow2,
OpenStyle3,
CloseStyle3, Color3,
Body3, UpperShadow3,
LowerShadow3,
OpenStyle4,
CloseStyle4, Color4,
Body4, UpperShadow4,
LowerShadow4,
OpenStyle5,
CloseStyle5, Color5,
Body5, UpperShadow5,
LowerShadow5,
Variation)
data4 <- matrix(nrow = N, ncol = 125)
#View(data3)
library(frbs)
##build a Two Line Mamdani model for regression
##we have 6*2+1=13 input variables and one output variable
## The matrix has 14 rows
##first row represent the type of the membership function whereas
## others are values of its parameters.
## the input variables are PreviousTrend, Color1, CandleBody1
##CandleUpperShadow1, CandleLowerShadow1, OpenStyle1,
##CloseStyle1, Color2, CandleBody2, CandleUpperShadow2,
##CandleLowerShadow2, OpenStyle2,CloseStyle2
##Output variable is the FollowingTrend
##1 means TRIANGLE, 2 means TRAPEZOID in left side,
##3 means TRAPEZOID in right side,
##4 means TRAPEZOID in the middle, 5 means GAUSSIAN,
##6 means SIGMOID, and 7 means BELL
#define var.labels.input
a <- matrix(c(5,5,3,4,4,4,5,5,3,4,4,4,
5,5,3,4,4,4,5,5,3,4,4,4,
5,5,3,4,4,4),nrow=1, byrow=TRUE)
#define nn
nn <- 30
for (i in nn:(N-30))
{
low1 <- data2[i,14]
high1 <- data2[i,13]
min1 <- data2[i,17]
max1 <- data2[i,16]
low2 <- data2[i,24]
high2 <- data2[i,23]
min2 <- data2[i,27]
max2 <- data2[i,26]
low3 <- data2[i,34]
high3 <- data2[i,33]
min3 <- data2[i,37]
max3 <- data2[i,36]
low4 <- data2[i,44]
high4 <- data2[i,43]
min4 <- data2[i,47]
max4 <- data2[i,46]
low5 <- data2[i,54]
high5 <- data2[i,53]
min5 <- data2[i,57]
max5 <- data2[i,56]
varinp.mf <- matrix(c(
2, 2*low1,low1,min1,NA,#candle1 open syle
1, low1,min1,(min1+max1)/2,NA,
1, min1, (min1+max1)/2, max1,NA,
1, (min1+max1)/2, max1,high1,NA,
3,max1,high1,2*high1,NA,
2,2*low1,low1,min1,NA,#candle1 close syle
1, low1,min1,(min1+max1)/2,NA,
1, min1, (min1+max1)/2, max1,NA,
1, (min1+max1)/2, max1,high1,NA,
3,max1,high1,2*high1,NA,
4, -4,-2,2,4, #color1
2, -4, -2, 0, NA,
3, 0, 2, 4, NA,
2, 0,0,0.1*a1,NA, #candlebody1
4, 0, 0.1*a1, 0.5*a1, 0.8*a1,
4, 0.5*a1, 0.8*a1, 1.15*a1, 1.5*a1,
3, 1.15*a1, 1.5*a1, 3*a1, NA,
2, 0,0,0.1*a2,NA,#uppershadow1
4, 0, 0.1*a2, 0.5*a2, 0.8*a2,
4, 0.5*a2, 0.8*a2, 1.15*a2,1.5*a2,
3, 1.15*a2, 1.5*a2, 3*a2, NA,
2, 0,0,0.1*a3,NA, #lowershadow1
4, 0, 0.1*a3, 0.5*a3, 0.8*a3,
4, 0.5*a3, 0.8*a3, 1.15*a3,1.5*a3,
3, 1.15*a3, 1.5*a3, 3*a3, NA,
2,2*low2,low2, min2,NA,#candle2 open syle
1, low2,min2,(min2+max2)/2,NA,
1, min2, (min2+max2)/2, max2,NA,
1, (min2+max2)/2, max2,high2,NA,
3,max2,high2,2*high2,NA,
2,2*low2,low2,min2,NA,#candle2 close syle
1, low2,min2,(min2+max2)/2,NA,
1, min2, (min2+max2)/2, max2,NA,
1, (min2+max2)/2, max2,high2,NA,
3,max2,high2,2*high2,NA,
4, -4,-2,2,4, #color2
2, -4, -2, 0, NA,
3, 0, 2, 4, NA,
2, 0,0,0.1*a1,NA, #candlebody2
4, 0, 0.1*a1, 0.5*a1, 0.8*a1,
4, 0.5*a1, 0.8*a1, 1.15*a1, 1.5*a1,
3, 1.15*a1, 1.5*a1, 3*a1, NA,
2, 0,0,0.1*a2,NA,#uppershadow2
4, 0, 0.1*a2, 0.5*a2, 0.8*a2,
4, 0.5*a2, 0.8*a2, 1.15*a2,1.5*a2,
3, 1.15*a2, 1.5*a2, 3*a2, NA,
2, 0,0,0.1*a3,NA, #lowershadow2
4, 0, 0.1*a3, 0.5*a3, 0.8*a3,
4, 0.5*a3, 0.8*a3, 1.15*a3,1.5*a3,
3, 1.15*a3, 1.5*a3, 3*a3, NA,
2, 2*low3,low3,min3,NA,#candle3 open syle
1, low3,min3,(min3+max3)/2,NA,
1, min3, (min3+max3)/2, max3,NA,
1, (min3+max3)/2, max3,high3,NA,
3,max3,high3,2*high3,NA,
2,2*low3,low3,min3,NA,#candle3 close syle
1, low3,min3,(min3+max3)/2,NA,
1, min3, (min3+max3)/2, max3,NA,
1, (min3+max3)/2, max3,high3,NA,
3,max3,high3,2*high3,NA,
4, -4,-2,2,4, #color3
2, -4, -2, 0, NA,
3, 0, 2, 4, NA,
2, 0,0,0.1*a1,NA, #candlebody3
4, 0, 0.1*a1, 0.5*a1, 0.8*a1,
4, 0.5*a1, 0.8*a1, 1.15*a1, 1.5*a1,
3, 1.15*a1, 1.5*a1, 3*a1, NA,
2, 0,0,0.1*a2,NA,#uppershadow3
4, 0, 0.1*a2, 0.5*a2, 0.8*a2,
4, 0.5*a2, 0.8*a2, 1.15*a2,1.5*a2,
3, 1.15*a2, 1.5*a2, 3*a2, NA,
2, 0,0,0.1*a3,NA, #lowershadow3
4, 0, 0.1*a3, 0.5*a3, 0.8*a3,
4, 0.5*a3, 0.8*a3, 1.15*a3,1.5*a3,
3, 1.15*a3, 1.5*a3, 3*a3, NA,
2, 2*low4,low4,min4,NA,#candle4 open syle
1, low4,min4,(min4+max4)/2,NA,
1, min4, (min4+max4)/2, max4,NA,
1, (min4+max4)/2, max4,high4,NA,
3,max4,high4,2*high4,NA,
2,2*low4,low4,min4,NA,#candle4 close syle
1, low4,min4,(min4+max4)/2,NA,
1, min4, (min4+max4)/2, max4,NA,
1, (min4+max4)/2, max4,high4,NA,
3,max4,high4,2*high4,NA,
4, -4,-2,2,4, #color4
2, -4, -2, 0, NA,
3, 0, 2, 4, NA,
2, 0,0,0.1*a1,NA, #candlebody4
4, 0, 0.1*a1, 0.5*a1, 0.8*a1,
4, 0.5*a1, 0.8*a1, 1.15*a1, 1.5*a1,
3, 1.15*a1, 1.5*a1, 3*a1, NA,
2, 0,0,0.1*a2,NA,#uppershadow4
4, 0, 0.1*a2, 0.5*a2, 0.8*a2,
4, 0.5*a2, 0.8*a2, 1.15*a2,1.5*a2,
3, 1.15*a2, 1.5*a2, 3*a2, NA,
2, 0,0,0.1*a3,NA, #lowershadow4
4, 0, 0.1*a3, 0.5*a3, 0.8*a3,
4, 0.5*a3, 0.8*a3, 1.15*a3,1.5*a3,
3, 1.15*a3, 1.5*a3, 3*a3, NA,
2, 2*low5,low5,min5,NA,#candle5 open syle
1, low5,min5,(min5+max5)/2,NA,
1, min5, (min5+max5)/2, max5,NA,
1, (min5+max5)/2, max5,high5,NA,
3,max5,high5,2*high5,NA,
2,2*low5,low5,min5,NA,#candle5 close syle
1, low5,min5,(min5+max5)/2,NA,
1, min5, (min5+max5)/2, max1,NA,
1, (min5+max5)/2, max1,high1,NA,
3,max5,high5,2*high5,NA,
4, -4,-2,2,4, #color1
2, -4, -2, 0, NA,
3, 0, 2, 4, NA,
2, 0,0,0.1*a1,NA, #candlebody5
4, 0, 0.1*a1, 0.5*a1, 0.8*a1,
4, 0.5*a1, 0.8*a1, 1.15*a1, 1.5*a1,
3, 1.15*a1, 1.5*a1, 3*a1, NA,
2, 0,0,0.1*a2,NA,#uppershadow5
4, 0, 0.1*a2, 0.5*a2, 0.8*a2,
4, 0.5*a2, 0.8*a2, 1.15*a2,1.5*a2,
3, 1.15*a2, 1.5*a2, 3*a2, NA,
2, 0,0,0.1*a3,NA, #lowershadow5
4, 0, 0.1*a3, 0.5*a3, 0.8*a3,
4, 0.5*a3, 0.8*a3, 1.15*a3,1.5*a3,
3, 1.15*a3, 1.5*a3, 3*a3, NA),
nrow = 5, byrow = FALSE)
##fuzzify the input data
data4[i,] <-fuzzifier(data3[i,], 30, a, varinp.mf)
}
#View(data3)
#options(error=recover)
#View(varinp.mf)
#View(data4)
#a new matrix with clear labels
data5 <- as.data.frame(matrix(nrow=N, ncol=30))
#5,5,3,4,4,4
#open style candle 1 with clear labels
data5[nn:(N-1), 1] <- max.col(data4[nn:(N-1), 1:5])
data5[,1] <- factor(data5[,1],
levels=c(1,2,3,4,5))
levels(data5[,1]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 1 with clear labels
data5[nn:(N-1), 2] <- max.col(data4[nn:(N-1), 6:10])
data5[,3] <- factor(data5[,2],
levels=c(1,2,3,4,5))
levels(data5[,2]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 1 with clear labels
data5[nn:(N-1), 3] <- max.col(data4[nn:(N-1), 11:13])
data5[,3] <- factor(data5[,3],
levels=c(1,2,3))
levels(data5[,3]) <-c("CROSS","BULLISH","BEARISH")
# candle body 1 with clear labels
data5[nn:(N-1), 4] <- max.col(data4[nn:(N-1), 14:17])
data5[,4] <- factor(data5[,4],
levels=c(1,2,3,4))
levels(data5[,4]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 1 with clear labels
data5[nn:(N-1), 5] <- max.col(data4[nn:(N-1), 18:21])
data5[,5] <- factor(data5[,5],
levels=c(1,2,3,4))
levels(data5[,5]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 1 with clear labels
data5[nn:(N-1), 6] <- max.col(data4[nn:(N-1), 22:25])
data5[,6] <- factor(data5[,6],
levels=c(1,2,3,4))
levels(data5[,6]) <- c("EQUAL","SHORT","MIDDLE","LONG")
#open style candle 2 with clear labels
data5[nn:(N-1), 7] <- max.col(data4[nn:(N-1), 26:30])
data5[,7] <- factor(data5[,7],
levels=c(1,2,3,4,5))
levels(data5[,7]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 2 with clear labels
data5[nn:(N-1), 8] <- max.col(data4[nn:(N-1), 31:35])
data5[,8] <- factor(data5[,8],
levels=c(1,2,3,4,5))
levels(data5[,8]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 2 with clear labels
data5[nn:(N-1), 9] <- max.col(data4[nn:(N-1), 36:38])
data5[,9] <- factor(data5[,9],
levels=c(1,2,3))
levels(data5[,9]) <-c("CROSS","BULLISH","BEARISH")
# candle body 2 with clear labels
data5[nn:(N-1), 10] <- max.col(data4[nn:(N-1), 39:42])
data5[,10] <- factor(data5[,10],
levels=c(1,2,3,4))
levels(data5[,10]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 2 with clear labels
data5[nn:(N-1), 11] <- max.col(data4[nn:(N-1), 43:46])
data5[,11] <- factor(data5[,11],
levels=c(1,2,3,4))
levels(data5[,11]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 2 with clear labels
data5[nn:(N-1), 12] <- max.col(data4[nn:(N-1), 47:50])
data5[,12] <- factor(data5[,12],
levels=c(1,2,3,4))
levels(data5[,12]) <- c("EQUAL","SHORT","MIDDLE","LONG")
#open style candle 3 with clear labels
data5[nn:(N-1), 13] <- max.col(data4[nn:(N-1), 51:55])
data5[,13] <- factor(data5[,13],
levels=c(1,2,3,4,5))
levels(data5[,13]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 3 with clear labels
data5[nn:(N-1), 14] <- max.col(data4[nn:(N-1), 56:60])
data5[,14] <- factor(data5[,14],
levels=c(1,2,3,4,5))
levels(data5[,14]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 3 with clear labels
data5[nn:(N-1), 15] <- max.col(data4[nn:(N-1), 61:63])
data5[,15] <- factor(data5[,15],
levels=c(1,2,3))
levels(data5[,15]) <-c("CROSS","BULLISH","BEARISH")
# candle body 3 with clear labels
data5[nn:(N-1), 16] <- max.col(data4[nn:(N-1), 64:67])
data5[,16] <- factor(data5[,16],
levels=c(1,2,3,4))
levels(data5[,16]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 3 with clear labels
data5[nn:(N-1), 17] <- max.col(data4[nn:(N-1), 68:71])
data5[,17] <- factor(data5[,17],
levels=c(1,2,3,4))
levels(data5[,17]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 3 with clear labels
data5[nn:(N-1), 18] <- max.col(data4[nn:(N-1), 72:75])
data5[,18] <- factor(data5[,18],
levels=c(1,2,3,4))
levels(data5[,18]) <- c("EQUAL","SHORT","MIDDLE","LONG")
#open style candle 4 with clear labels
data5[nn:(N-1), 19] <- max.col(data4[nn:(N-1), 76:80])
data5[,19] <- factor(data5[,19],
levels=c(1,2,3,4,5))
levels(data5[,19]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 4 with clear labels
data5[nn:(N-1), 20] <- max.col(data4[nn:(N-1), 81:85])
data5[,20] <- factor(data5[,20],
levels=c(1,2,3,4,5))
levels(data5[,20]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 4 with clear labels
data5[nn:(N-1), 21] <- max.col(data4[nn:(N-1), 86:88])
data5[,21] <- factor(data5[,21],
levels=c(1,2,3))
levels(data5[,21]) <-c("CROSS","BULLISH","BEARISH")
# candle body 4 with clear labels
data5[nn:(N-1), 22] <- max.col(data4[nn:(N-1), 89:92])
data5[,22] <- factor(data5[,22],
levels=c(1,2,3,4))
levels(data5[,22]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 4 with clear labels
data5[nn:(N-1), 23] <- max.col(data4[nn:(N-1), 93:96])
data5[,23] <- factor(data5[,23],
levels=c(1,2,3,4))
levels(data5[,23]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 4 with clear labels
data5[nn:(N-1), 24] <- max.col(data4[nn:(N-1), 97:100])
data5[,24] <- factor(data5[,24],
levels=c(1,2,3,4))
levels(data5[,24]) <- c("EQUAL","SHORT","MIDDLE","LONG")
#open style candle 5 with clear labels
data5[nn:(N-1), 25] <- max.col(data4[nn:(N-1), 101:105])
data5[,25] <- factor(data5[,25],
levels=c(1,2,3,4,5))
levels(data5[,25]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 5 with clear labels
data5[nn:(N-1), 26] <- max.col(data4[nn:(N-1), 106:110])
data5[,26] <- factor(data5[,26],
levels=c(1,2,3,4,5))
levels(data5[,26]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 5 with clear labels
data5[nn:(N-1), 27] <- max.col(data4[nn:(N-1), 111:113])
data5[,27] <- factor(data5[,27],
levels=c(1,2,3))
levels(data5[,27]) <-c("CROSS","BULLISH","BEARISH")
# candle body 5 with clear labels
data5[nn:(N-1), 28] <- max.col(data4[nn:(N-1), 114:117])
data5[,28] <- factor(data5[,28],
levels=c(1,2,3,4))
levels(data5[,28]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 5 with clear labels
data5[nn:(N-1), 29] <- max.col(data4[nn:(N-1), 118:121])
data5[,29] <- factor(data5[,29],
levels=c(1,2,3,4))
levels(data5[,29]) <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 5 with clear labels
data5[nn:(N-1), 30] <- max.col(data4[nn:(N-1), 122:125])
data5[,30] <- factor(data5[,30],
levels=c(1,2,3,4))
levels(data5[,30]) <- c("EQUAL","SHORT","MIDDLE","LONG")
#Buy/Sell Signals with clear labels
data2 <- data.frame(data2)
# data2$Signal <- ifelse((data2$Trend < 0 & # data2$Pips > 70) |
# (data2$Trend > 0 &
# data2$Pips) < -70, 1, 2)
data2$Signal <- ifelse(data2$Pips > 0, 1,2)
data5[,31] <- data2[,63]
data5[ ,31] <- factor(data2[ ,63])
levels(data5[,31]) <- c("Buy", "Sell")
#data5[,31]
#barplot(table(data2$Signal))
#name the columns
colnames(data5) <- c("OpenStyle1",
"CloseStyle1", "Color1",
"Body1", "UpperShadow1",
"LowerShadow1", "OpenStyle2",
"CloseStyle2",
"Color2", "Body2", "UpperShadow2",
"LowerShadow2",
"OpenStyle3",
"CloseStyle3", "Color3",
"Body3", "UpperShadow3",
"LowerShadow3",
"OpenStyle4",
"CloseStyle4", "Color4",
"Body4", "UpperShadow4",
"LowerShadow4",
"OpenStyle5",
"CloseStyle5", "Color5",
"Body5", "UpperShadow5",
"LowerShadow5",
"Signal")
barplot(table(data5$Signal))
#View(data5)
#barplot(table(data5$PreviousTrend))
#barplot(table(data5$Body1))
#barplot(table(data5$UpperShadow1))
#barplot(table(data5$LowerShadow1))
#barplot(table(data5$OpenStyle1))
#barplot(table(data5$CloseStyle1))
#barplot(table(data5$Variation))
#split the data into train and test
train <- data5[nn:(N-100),]
test <- data5[(N-99):(N-nn),]
We have fuzzified the input data. Below label the input data with the maximum value of fuzzify lingusitic variable. We will use this linguistic variables instead of the initial numerical values in building our Fuzzy Candlestick Patterns Forecasting Algorithm. Read the post on how to code stop loss and take profit in MQL5.
#View(data3)
#options(error=recover)
#View(varinp.mf)
#View(data4)
#a new matrix with clear labels
data5 <- as.data.frame(matrix(nrow=N, ncol=20))
#previous trend with clear labels
data5[3:(N-1), 1] <- max.col(data4[3:(N-1), 1:8])
data5[,1] <- factor(data5[,1],
levels=c(1,2,3,4,5,6,7,8))
levels(data5[,1]) <-c("EXTREME_BEARISH", "STRONG_BEARISH",
"NORMAL_BEARISH", "WEAK_BEARISH",
"RANGING", "NORMAL_BULLISH",
"STRONG_BULLISH", "EXTREME_BULLISH")
#open style candle 1 with clear labels
data5[3:(N-1), 2] <- max.col(data4[3:(N-1), 9:13])
data5[,2] <- factor(data5[,2],
levels=c(1,2,3,4,5))
levels(data5[,2]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 1 with clear labels
data5[3:(N-1), 3] <- max.col(data4[3:(N-1), 14:18])
data5[,3] <- factor(data5[,3],
levels=c(1,2,3,4,5))
levels(data5[,3]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 1 with clear labels
data5[3:(N-1), 4] <- max.col(data4[3:(N-1), 19:21])
data5[,4] <- factor(data5[,4],
levels=c(1,2,3))
levels(data5[,4]) <-c("CROSS","BULLISH","BEARISH")
# candle body 1 with clear labels
data5[3:(N-1), 5] <- max.col(data4[3:(N-1), 22:25])
data5[,5] <- factor(data5[,5],
levels=c(1,2,3,4))
levels(data5[,5]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 1 with clear labels
data5[3:(N-1), 6] <- max.col(data4[3:(N-1), 26:29])
data5[,6] <- factor(data5[,6],
levels=c(1,2,3,4))
levels(data5[,6]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 1 with clear labels
data5[3:(N-1), 7] <- max.col(data4[3:(N-1), 30:33])
data5[,7] <- factor(data5[,7],
levels=c(1,2,3,4))
levels(data5[,7]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
#open style candle 2 with clear labels
data5[3:(N-1), 8] <- max.col(data4[3:(N-1), 34:38])
data5[,8] <- factor(data5[,8],
levels=c(1,2,3,4,5))
levels(data5[,8]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 2 with clear labels
data5[3:(N-1), 9] <- max.col(data4[3:(N-1), 39:43])
data5[,9] <- factor(data5[,9],
levels=c(1,2,3,4,5))
levels(data5[,9]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 2 with clear labels
data5[3:(N-1), 10] <- max.col(data4[3:(N-1), 44:46])
data5[,10] <- factor(data5[,10],
levels=c(1,2,3))
levels(data5[,10]) <-c("CROSS","BULLISH","BEARISH")
# candle body 2 with clear labels
data5[3:(N-1), 11] <- max.col(data4[3:(N-1), 47:50])
data5[,11] <- factor(data5[,11],
levels=c(1,2,3,4))
levels(data5[,11]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 2 with clear labels
data5[3:(N-1), 12] <- max.col(data4[3:(N-1), 51:54])
data5[,12] <- factor(data5[,12],
levels=c(1,2,3,4))
levels(data5[,12]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 2 with clear labels
data5[3:(N-1), 13] <- max.col(data4[3:(N-1), 55:58])
data5[,13] <- factor(data5[,13],
levels=c(1,2,3,4))
levels(data5[,13]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
#open style candle 3 with clear labels
data5[3:(N-1), 14] <- max.col(data4[3:(N-1), 59:63])
data5[,14] <- factor(data5[,14],
levels=c(1,2,3,4,5))
levels(data5[,14]) <-c("OPEN_LOW", "OPEN_EQUAL_LOW",
"OPEN_EQUAL","OPEN_EQUAL_HIGH",
"OPEN_HIGH")
#close style candle 3 with clear labels
data5[3:(N-1), 15] <- max.col(data4[3:(N-1), 64:68])
data5[,15] <- factor(data5[,15],
levels=c(1,2,3,4,5))
levels(data5[,15]) <-c("CLOSE_LOW", "CLOSE_EQUAL_LOW",
"CLOSE_EQUAL", "CLOSE_EQUAL_HIGH",
"CLOSE_HIGH")
#color candle 3 with clear labels
data5[3:(N-1), 16] <- max.col(data4[3:(N-1), 69:71])
data5[,16] <- factor(data5[,16],
levels=c(1,2,3))
levels(data5[,16]) <-c("CROSS","BULLISH","BEARISH")
# candle body 3 with clear labels
data5[3:(N-1), 17] <- max.col(data4[3:(N-1), 72:75])
data5[,17] <- factor(data5[,17],
levels=c(1,2,3,4))
levels(data5[,17]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle upper shadow 3 with clear labels
data5[3:(N-1), 18] <- max.col(data4[3:(N-1), 76:79])
data5[,18] <- factor(data5[,18],
levels=c(1,2,3,4))
levels(data5[,18]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
# candle lower shadow 3 with clear labels
data5[3:(N-1), 19] <- max.col(data4[3:(N-1), 80:83])
data5[,19] <- factor(data5[,19],
levels=c(1,2,3,4))
levels(data5[,19]) <-Body2 <- c("EQUAL","SHORT","MIDDLE","LONG")
#following trend with clear labels
data5[3:(N-1), 20] <- max.col(data4[3:(N-1), 84:91])
data5[,20] <- factor(data5[,20],
levels=c(1,2,3,4,5,6,7,8))
levels(data5[,20]) <-c("EXTREME_BEARISH", "STRONG_BEARISH",
"NORMAL_BEARISH", "WEAK_BEARISH",
"RANGING", "NORMAL_BULLISH",
"STRONG_BULLISH", "EXTREME_BULLISH")
#name the columns
colnames(data5) <- c("PreviousTrend", "OpenStyle1",
"CloseStyle1", "Color1",
"Body1", "UpperShadow1",
"LowerShadow1", "OpenStyle2", "CloseStyle2",
"Color2", "Body2", "UpperShadow2",
"LowerShadow2",
"OpenStyle3",
"CloseStyle3", "Color3",
"Body3", "UpperShadow3",
"LowerShadow3",
"Variation")
We have turned the fuzzified data into fuzzy labels.Now we need to split the data into train and test. We will use the train dataset for building the model. Once we have the model, we will use the test dataset to test the accuracy of the model. Test dataset is also known as the Validation Set. This is something very important. In the validation data set we use the data that the model has never seen before.
#View(data5) #split the data into train and test train <- data5[nn:(N-100),] test <- data5[(N-99):(N-nn),]
First we will use the train dataset for training our model and then use that trained model to make predictions on the test data and check the accuracy for the predictions made by our model.
Data Mining Using AdaBoost
The first model that we build is a Decision Tree model. Data mining algorithms look for repeatable patterns in the data. This is what we also do as technical traders. As technical traders, we look for patterns that can predict the market. Most popular chart patterns are the double top and the double bottom, triple top and tripe bottom, head and shoulder pattern, triangle pattern, wedge pattern etc. These patterns are important in predicting trend reversal and trend continuation. AdaBoost Decision Tree model uses boosting.
#using adaBag algorithm for data mining
library(rpart)
library(adabag)
#first we try boosting
f <-Signal~OpenStyle1+CloseStyle1+
Color1+Body1+ UpperShadow1+LowerShadow1+
OpenStyle2+CloseStyle2+Color2+Body2+
UpperShadow2+LowerShadow2+
OpenStyle3+CloseStyle3+
Color3+Body3+ UpperShadow3+LowerShadow3+
OpenStyle4+CloseStyle4+
Color4+Body4+ UpperShadow4+LowerShadow4+
OpenStyle5+CloseStyle5+
Color5+Body5+ UpperShadow5+LowerShadow5
adaboost1<-boosting(f ,
data=train, boos=TRUE,
mfinal=200,coeflearn='Breiman')
#importanceplot(adaboost1)
pred1 <- predict.boosting(adaboost1, newdata=test) pred1$confusion pred1$error > pred1$confusion
Observed Class
Predicted Class Buy Sell
Buy 36 6
Sell 22 6
> pred1$error
[1] 0.4
I have used the AdaBoost Decision Tree Algorithm to build a model that I used to then make predictions on the test data. The error is 0.4. You can say our model is giving 40% wrong predictions and 60% correct predictions. Important question is how to improve the accuracy of our model to above 80%. Let’s try that now. One approach is to increase the input data from three candlesticks to five candlesticks and see if this improves the correct prediction percentage.
Fuzzy Candlestick Patterns Neural Network Model
Another approach is to use another algorithm like RandomForest or a Deep Learning Neural Network. Below I have used a simple Multilayer Perceptron in building a Fuzzy Candlestick Patterns Neural Network Model.
library(RSNNS)
m4 <- mlp(data4[nn:(N-100),1:125],
data2[nn:(N-100),63],
size = 100,
learnFunc = "Rprop",
shufflePatterns = FALSE,
maxit = 1000)
#in sample predictions
yhat3 <- predict(m4)
train[,32] <- factor(yhat3, levels=c(1,2))
levels(train[,32]) <- c("Buy", "Sell")
caret::confusionMatrix(xtabs(~train[,32]+train[,31]))
#out of sample predictions
yhat4 <- predict(m4, data4[(N-99):(N-nn),1:125])
test[,32] <- factor(yhat4,
levels=c(1,2))
levels(test[,32]) <- c("Buy", "Sell")
#barplot(table(test1[,21]))
caret::confusionMatrix(xtabs(~test[,32] + test[,31]))
First I train the MLP on the train dataset. Once I trained the MLP model, I use the test data to see how good the model is! Below I have shown the confustion matrix for the validation set. You can see that the model achieved a predictive accuracy of 82% which is good for our purposes.
Confusion Matrix and Statistics
test[, 31]
test[, 32] Buy Sell
Buy 58 12
Sell 0 0
Accuracy : 0.8286
95% CI : (0.7197, 0.9082)
No Information Rate : 0.8286
P-Value [Acc > NIR] : 0.576303
Kappa : 0
Mcnemar's Test P-Value : 0.001496
Sensitivity : 1.0000
Specificity : 0.0000
Pos Pred Value : 0.8286
Neg Pred Value : NaN
Prevalence : 0.8286
Detection Rate : 0.8286
Detection Prevalence : 1.0000
Balanced Accuracy : 0.5000
'Positive' Class : Buy
We can improve the predictive accuracy of the model by using deep learning. Did you take a look at my course R Deep Learning for Traders? Deep learning is much more powerful as compared to machine learning.
Conclusion
In this post I developed a fuzzy candlestick forecasting algorithm. I used five candlesticks in my model. I did not use any other indicator and achieved a predictive accuracy of 82%. This model needs more work and I think we can improve the predictive accuracy above 90% using deep learning. What this model shows is that we can use candlestick patterns in predicting price. As technical traders we have known this for a long time by just looking at the charts. Now we can use machine learning to prove that candlestick patterns do have predictive powers.